
Einblicke in die Rolle von „large language models“ in der urologischen Bildung
Die rasante Entwicklung der künstlichen Intelligenz (KI) hat auch das Feld der Medizin erfasst. In einer vergleichenden Analyse wurden große Sprachmodelle wie ChatGPT und BingAI anhand des In-Service-Assessments 2022 (ISA) des European Board of Urology (EBU) getestet. Die Modelle erzielten beeindruckende Ergebnisse, wiesen aber einige verbesserungswürdige Schwächen auf.
Keypoints
-
Mit Fehlerquoten zwischen 19% und 42% erreichen die aktuellen LLM derzeit kein zufriedenstellendes Ergebnis in Bezug auf die erfolgreiche Integration in die medizinische Ausbildung.
-
Künstliche Intelligenz (KI) hat ein enormes Potenzial im Bereich Bildung und Gesundheitswesen.
-
KI-Technologie befindet sich noch in den Kinderschuhen.
-
Die Entwicklung von KI, insbesondere in sensiblen Bereichen der Medizin, erfordert sorgfältige Planung, rigorose Tests und kontinuierliche Verfeinerung.
-
Ethische Überlegungen, Datenschutz und Systemzuverlässigkeit sind von entscheidender Bedeutung.
-
In naher Zukunft wird dennochder Wechsel vom traditionellen Lehrbuch hin zu großen Sprachmodellen zur Wissensvermittlung stattfinden.
In den letzten Jahrzehnten hat die rapide Entwicklung der KI zahlreiche Aspekte des täglichen Lebens und der Wissenschaft revolutioniert. Im Bereich der KI stellen „large language models“ (LLM) eine besondere Untergruppe dar, die sich durch ihre tiefgreifende Lernkapazität, bekannt als „deep learning“, auszeichnet. Diese Modelle basieren auf neuronalen Netzwerken, bestehend aus Millionen oder Milliarden von einzelnen künstlichen Neuronen, die in Schichten angeordnet und miteinander verbunden sind. Jedes Neuron führt einfache Berechnungen durch, wie das Gewichten von Eingabedaten und die Anwendung einer Aktivierungsfunktion. Wenn diese Neuronen jedoch miteinander interagieren, entsteht eine emergente Intelligenz. Das Netzwerk ist dann analog zum menschlichen Gehirn in der Lage, komplexe Aufgaben wie Bilderkennung, Sprachverarbeitung oder sogar autonome Fahrzeugsteuerung zu bewältigen.1,2 LLM werden mithilfe umfangreicher Datensätze trainiert, die aus verschiedenen öffentlichen Quellen stammen. Dadurch können sie kontextuell relevante und kohärente Antworten auf Anfragen in natürlicher Sprache generieren. KI-Chatbots kommunizieren mit Menschen, indem sie die Bedeutung ihrer Anfragen interpretieren und entsprechende Antworten liefern.1,3
Die interaktiven Fähigkeiten von LLM haben das Interesse von Ärzten und Forschern geweckt, insbesondere hinsichtlich ihrer potenziellen Anwendungen in der medizinischen Information und Bildung. Derzeit gibt es jedoch nur begrenzte veröffentlichte Daten zur Wirksamkeit von LLM in der medizinischen Ausbildung und ihrer Leistung bei medizinischen Prüfungen, insbesondere im Bereich der Urologie. In unseren Vergleichsanalysen haben wir die Präzision, Verlässlichkeit und Leistungsfähigkeit dreier LLM in der Beantwortung von Prüfungsfragen aus verschiedenen urologischen Teilgebieten beurteilt.4,5
Studiendesign
ChatGPT-3.5, ChatGPT-4 und Bing AI wurden im August 2023 in zwei Testphasen mit jeweils mindestens 48 Stunden Abstand mittels 100 Multiple-Choice-Fragen (MCQ) aus dem „In-Service-Assessment“ (ISA) 2022 des European Board of Urology (EBU) geprüft. Im Falle von divergierenden Antworten wurde eine zusätzliche Konsensfindungsrunde eingeführt, um definitive Antworten zu bestimmen.
Der primäre Endpunkt umfasste die Anzahl an korrekt beantworteten Fragen („rate of correct answers“; RoCA). Zudem wurde die Konsistenz der LLM-Antworten über zwei Testphasen analysiert sowie die Leistung der LLM bei Fragen unterschiedlicher Komplexität beurteilt. Die Bestehensgrenze von 61% aus dem schriftlichen EBU-Examen des Jahres 2022 wurde als maßgebliche Benchmark herangezogen. Die 100 MCQ wurden anhand der Antwortmuster von 727 Prüflingen des ISA 2022, basierend auf ihrer Genauigkeitsverteilung, in vier Komplexitätsquartile (Q1–Q4) kategorisiert. Der mediane RoCA-Score der Prüflinge betrug 72,1% (Interquartilsbereich; IQR: 54,5–84,4). Zehn Wochen nach der initialen Konsensphase wurde eine vierte Testrunde zur Evaluierung eines möglichen Wissenszuwachses durchgeführt.
Die Sprachmodelle
-
ChatGPT-3.5: ist ein hochmodernes KI-Sprachmodell, das von OpenAI entwickelt und im November 2022 eingeführt wurde. Es wurde auf umfangreichen Daten trainiert, um Fragen zu beantworten, Informationen bereitzustellen und sich an vielfältigen Textkonversationen zu beteiligen. Das Wissen von ChatGPT-3.5 ist auf Informationen beschränkt, die bis zu seinem Trainingsstichtag im September 2021 verfügbar waren.
-
ChatGPT-4: wurde im März 2023 veröffentlicht und stellt eine Weiterentwicklung seines Vorgängers dar, mit verbesserten Fähigkeiten im Verständnis von Kontexten und bei der Generierung kohärenter Antworten. Ein herausragendes Merkmal von ChatGPT-4 ist seine Fähigkeit, aktuelle Informationen aus Internetsuchmaschinen abzurufen, was es von seinem Vorgänger unterscheidet.
-
BingAI: wurde von Microsoft in Zusammenarbeit mit OpenAI entwickelt und im Februar 2023 eingeführt. Es kombiniert das ChatGPT-4-LLM von OpenAI mit Microsofts Prometheus-Suchwerkzeug. Es verwendet eine transformerbasierte semantische „ranking engine“ für das kontextuelle Verständnis und wird ständig durch das KI-Modell verbessert. Besonders hervorzuheben ist, dass Bing AI Informationsquellen eindeutig zitiert und Echtzeitdaten aus Internetsuchmaschinen abruft.
Ergebnisse
Über die drei Testdurchgänge hinweg erzielte ChatGPT-3.5 eine RoCA von 58%, 62% und 59%. ChatGPT-4 hingegen erreichte 63%, 77% und 77%, während Bing AI mit 81%, 73% und 77% abschnitt (p≤0,010 in jeder Runde; Abb. 1).4
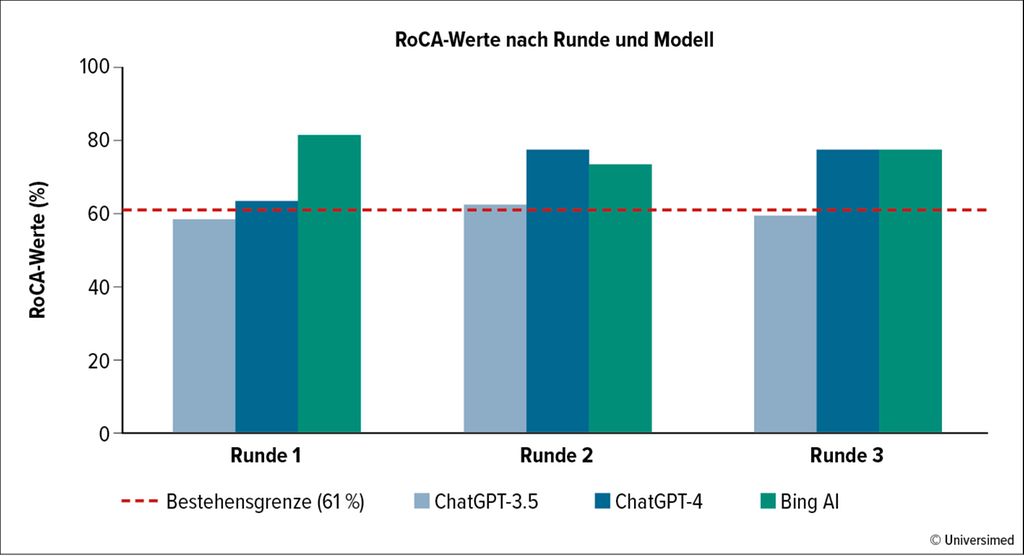
Abb. 1: Prozentual richtige Antworten (RoCA = „rate of correct answers“) pro Fragerunde (nach Kollitsch L et al. 2024)4
Die Übereinstimmungsraten zwischen der ersten und zweiten Runde lagen für ChatGPT-3.5 bei 84% (κ=0,67, p<0,001), für ChatGPT-4 bei 74% (κ=0,40, p<0,001) und für BingAI bei 76% (κ=0,33, p<0,001). Die Stärke der Übereinstimmung wird dabei wie folgt klassifiziert: schwach (κ<0,3), moderat (κ=0,3–0,6) und stark (κ>0,6).4
Alle LLM demonstrierten eine inverse Korrelation zwischen den erzielten RoCA-Werten und der Komplexität der Fragen, wobei bei anspruchsvolleren Fragen eine statistisch signifikante Abnahme der Leistung festgestellt wurde (p<0,001, Tab. 1).4
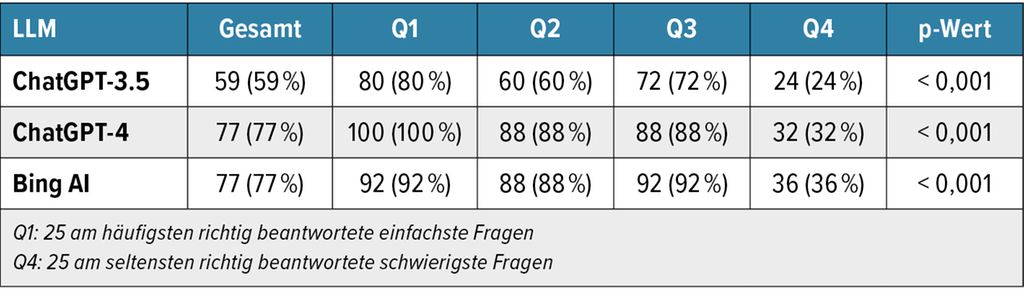
Tab. 1: Schwierigkeitsgrade entsprechen den vier Quartilen der RoCA der 100 Fragen der ISA 2022 basierend auf den Antworten von 727 Prüfungsteilnehmer:innen (nach Kollitsch L et al. 2024)4
Durch die Aufschlüsselung der Fragen in verschiedene Themengebiete wurden erhebliche Wissensunterschiede sichtbar (Tab. 2).5 Die 4. Testrunde, die 10 Wochen nach der Konsensusrunde erfolgte, ergab keine signifikante Verbesserung in der Leistung der Modelle.4
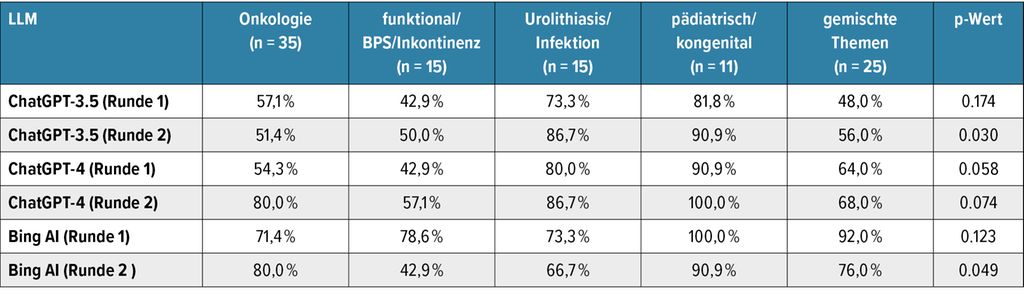
Tab. 2: Prozentuale Verteilung der korrekten Antworten der einzelnen LLM, aufgeschlüsselt nach urologischen Themengebieten (May M et al. 2024)5
Diskussion und Ausblick
Die Studien verdeutlichen, dass große Sprachmodelle wie ChatGPT-4 und Bing AI bereits jetzt in der Lage sind, Prüfungen im Bereich der Urologie zu bestehen. Dennoch erreichen die LLM derzeit mit Fehlerraten von 19% bis 42% nicht das erforderliche Niveau an urologischem Verständnis für eine effektive Ausbildung. Dies verdeutlicht, dass die Modelle, obwohl sie teilweise beeindruckende Leistungen erbringen, noch nicht die Genauigkeit und Zuverlässigkeit bieten, die in der medizinischen Ausbildung und Praxis erforderlich sind. Besonders komplexe Fragen stellen eine erhebliche Herausforderung dar und führen zu einem signifikanten Leistungsabfall der Modelle. Die erheblichen Wissensunterschiede auf den verschiedenen Themenuntergebieten unterstreichen die Notwendigkeit einer gezielten Weiterentwicklung und Schulung der Modelle, um ihre Leistung über alle Themen hinweg zu verbessern. Weiters bieten die Ergebnisse wichtige Einblicke in die aktuelle Einschränkung der adaptiven Lernfähigkeit von LLM, da sie ausschließlich aus ihren ursprünglichen Trainingsdaten Antworten generieren können. Dies betont die Bedeutung fortlaufender Updates, kontinuierlichen Trainings und aktiver Wartung von LLM, damit sie als zuverlässige Werkzeuge für den Erwerb medizinischen Wissens dienen können.
Betrachtet man die Ergebnisse anderer rezent veröffentlichter Studien, in denen LLM zu verschiedenen medizinischen Prüfungen befragt wurden, lassen sich folgende Schlüsselfaktoren definieren, die die Leistung von LLM beeinflussen:
-
Umfang der Trainingsdaten: Modelle, die mittels umfassender medizinischer Literatur und Ressourcen trainiert wurden, zeigen eine überlegene Leistung (z.B. „Med PaLM-2“ oder „Uro-Chat“).6–12
-
Fragenkomplexität: Einfache Fragen führen zu höheren Genauigkeitsraten, während komplexe, nuancierte Fragen größere Herausforderungen darstellen.6,10,12–21
-
Mehrsprachigkeit: Die Qualität der Leistung in anderen Sprachen als Englisch variiert.8,12,13,20
-
Spezifisches medizinisches Wissen: Die Leistung variiert erheblich, wenn spezifisches Wissen in Unterbereichen erforderlich ist.9,10,12,14–16,19,22,23
-
Zuverlässigkeit und Reproduzierbarkeit: Es ist wichtig, die Zuverlässigkeit und Reproduzierbarkeit der generierten Antworten kritisch zu bewerten und weiter zu erforschen, um die Verbreitung von Fehlinformationen zu vermeiden.9,14,17,18,23
Zukünftig hätte KI das Potenzial, viel Zeit zu sparen, indem sie personalisierte Lernerfahrungen anbieten könnte, die an individuelle Stile und Geschwindigkeiten angepasst sind. Darüber hinaus könnte sie beim Navigieren durch umfangreiche medizinische Literatur behilflich sein. Sie könnte den Wissenserwerb erleichtern und beschleunigen und für die Erstellung von Lernmaterialien oder Bildungspräsentationen nützlich sein. Diese gesteigerte Effizienz würde es medizinischen Fachkräften ermöglichen, sich mehr auf das Verständnis und die Anwendung von Wissen zu konzentrieren, anstatt viel Zeit mit der Informationsbeschaffung zu verbringen. Unumgänglich ist aber eine spezialisierte, zugeschnittene medizinische Ausbildung der LLM, bevor diese Werkzeuge zuverlässig zur Aneignung von fachspezifischem Wissen empfohlen und effektiv in die medizinische Ausbildung integriert werden können. Die zu erwartenden Vorteile sind beträchtlich, da LLM durch ihre Fähigkeit, umfangreiche Datenmengen schnell zu verarbeiten und relevante Informationen bereitzustellen, die Lernprozesse von Medizinstudenten und Fachkräften erheblich verbessern könnten. Gleichzeitig müssen aber ethische Überlegungen, die Sicherstellung der Qualität der bereitgestellten Informationen und das rationale Denken hinter den von LLM generierten Antworten im Vordergrund stehen und weiter untersucht werden, um eine verantwortungsvolle und effektive Nutzung dieser Technologie gewährleisten zu können.
Studien zeigten, dass LLM im Vergleich zu anderen sozialen Medien wie TikTok, YouTube und Instagram eine zuverlässigere Quelle für medizinische Informationen zu sein scheinen.24 In einer Querschnittsanalyse wurden Genauigkeit, Verständlichkeit und Anwendbarkeit der von vier verschiedenen LLM generierten Antworten in Bezug auf die fünf häufigsten Suchanfragen zu Prostata-, Blasen-, Nieren- und Hodenkrebs gemäß Google Trends bewertet.25 Ihre Ergebnisse zeigen, dass KI-Chatbots zwar genaue und qualitativ hochwertige Antworten liefern können, die Verwendung komplexer medizinischer Terminologie jedoch eine Herausforderung für Benutzer ohne medizinischen Hintergrund darstellen kann. Die Informationsqualität wurde mit 80% bewertet, ohne dass Fehlinformationen gemeldet wurden.
Bei einer Untersuchung zur aktuellen Nutzung von LLM unter Urolog:innen gaben 47,7% der befragten 456 Ärzt:innen an, ChatGPT oder andere LLM in ihrer akademischen Praxis zu verwenden.26 Etwa 19,8% integrierten KI in ihre klinische Arbeit. Allerdings äußerten 62,2% ethische Bedenken, und 53% sahen Einschränkungen bei der Anwendung von ChatGPT. Häufig genannte Probleme waren Ungenauigkeiten, mangelnde Spezifität und variierende Antworten.26
Die WHO hat einen ethischen Rahmen für die Nutzung von LLM im Gesundheitswesen und in der Medizin entwickelt, der festlegt, dass die Kontrolle des Menschen über medizinische Entscheidungen und die Autorität der Anbieter unter Verwendung gültiger Patienteninformationen entscheidend sind. Der Schutz der Datenprivatsphäre und die Einholung einer informierten Zustimmung sind ebenfalls unerlässlich. Öffentliche Konsultationen und Debatten, die ausreichende Informationen bieten, sollten jedem Entwurf oder Einsatz eines KI-Systems vorausgehen.27 Wenn diese ethischen Standards eingehalten werden können und wenn LLM technisch verbessert oder so trainiert werden können, dass sie stets aktuelle und leitlinienkonforme medizinische Kenntnisse demonstrieren, wird die KI eine entscheidende Rolle in der Medizin und Urologie spielen. Es liegt ein spannender Weg vor uns und jeder Schritt bringt uns dem Ziel näher, das volle Leistungsvermögen der KI zu realisieren und es vor allem auch für uns gewinnbringend zu nutzen.
Literatur:
1 Ray PP: IOTCPS 2023; 3: 121-54 2 Borchers M: Uro-News 2023; 10: 52-3 3 Eysenbach G et al.: JMIR Med Educ 2023; 9: doi: 10.2196/46885 4 Kollitsch L et al.: World J Urol 2024; 42(1): 20 5 May M et al.: Urol Int 2024; 108(4): 359-66 6 Ali R et al.: Neurosurgery 2023; 93(6): 1353-65 7 Azizoğlu M, Okur MH: doi.org/10.21203/rs.3.rs-3018641/v1 8 Lewandowski M et al.: Clin Exp Dermatol 2024; 49(7): 686-91 9 May M et al.: Eur Urol Oncol 2024; 7(1): 155-6 10 Moshirfar M et al.: Cureus 2023; 15(6): e40822 11 Oh N et al.: Ann Surg Treat Res 2023; 104(5): 269-73 12 Takagi S et al.: JMIR Med Educ 2023; 9: e48002 13 Alfertshofer M et al.: Ann Biomed Eng 2024; 52(6): 1542-5 14 Antaki F et al.: Ophthalmology Sci 2023; 3(4): 100324 15 Guerra GA et al.: World Neurosurg 2023; 179: e160-5 16 Hoch CC et al.: Eur Arch Otorhinolaryngolog 2023; 280(9): 4271-8 17 Huynh LM et al.: Urol Pract 2023; 10(4): 409-15 18 Kung TH et al.: PLOS Digit Health 2023; 2(2): e0000198 19 Saad A et al.: Surgeon 2023; 21(5): 263-6 20 Weng T-L et al.: J Chin Med Assoc 2023; 86(8): 762-6 21 May M et al.: Urology 2024; 183: 302-3 22 Suchman K et al.: Am J Gastroenterol 2023; 118(12): 2280-2 23 Thirunavukarasu AJ et al.: JMIR Med Educ 2023; 9: e46599 24 Teoh JY-C et al.: BJU Int 2021; 128(4): 397 25 Musheyev D et al.: Eur Urol 2024; 85(1): 13-6 26 Eppler M et al.: Eur Urol 2024; 85(2): 146-53 27 Harrer S et al.: EBioMedicine 2023; 90: 104512
Das könnte Sie auch interessieren:

Prof. Mani Menon – Roboterchirurgie: vom Zweifel zum Durchbruch
Prof. Mani Menon spricht im ÖGU-Podcast mit Univ.-Prof. Shahrokh F. Shariat über die Anfänge der robotischen Chirurgie, prägende Rückschläge, Mentoren, Mut und Menschlichkeit in der Medizin.

„Buried penis“: Herausforderungen in der rekonstruktiven Urologie
Die rekonstruktive Urologie erfordert zunehmend individualisierte operative Konzepte bei komplexen anatomischen und funktionellen Ausgangssituationen. Der „buried penis“ stellt dabei ...

PCNL-Indikationen in Zeiten von flexibler Ureterorenoskopie mit Absaugung?
In der Behandlung von Nierensteinen, die größer als 2cm sind, spielt die perkutane Nephrolithotomie (PCNL) weiterhin eine wichtige Rolle. Die flexible Ureterorenoskopie (URS) mit ...